Posted by willcritchlow
When you’ve got one of Google’s most helpful and empathetic voices willing to answer your most pressing SEO questions, what do you ask? Will Critchlow recently had the honor of interviewing Google’s John Mueller at SearchLove London, and in this week’s edition of Whiteboard Friday he shares his best lessons from that session, covering the concept of Domain Authority, the great subdomain versus subfolder debate, and a view into the technical workings of noindex/nofollow.

Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Hi, Whiteboard Friday fans. I’m Will Critchlow from Distilled, and I found myself in Seattle, wanted to record another Whiteboard Friday video and talk through some things that I learned recently when I got to sit down with John Mueller from Google at our SearchLove London conference recently.
So I got to interview John on stage, and, as many of you may know, John is a webmaster relations guy at Google and really a point of contact for many of us in the industry when there are technical questions or questions about how Google is treating different things. If you followed some of the stuff that I’ve written and talked about in the past, you’ll know that I’ve always been a little bit suspicious of some of the official lines that come out of Google and felt like either we don’t get the full story or we haven’t been able to drill in deep enough and really figure out what’s going on.
I was under no illusions that I might be able to completely fix this this in one go, but I did want to grill John on a couple of specific things where I felt like we hadn’t maybe asked things clearly enough or got the full story. Today I wanted to run through a few things that I learned when John and I sat down together. A little side note, I found it really fascinating doing this kind of interview. I sat on stage in a kind of journalistic setting. I had never done this before. Maybe I’ll do a follow-up Whiteboard Friday one day on things I learned and how to run interviews.
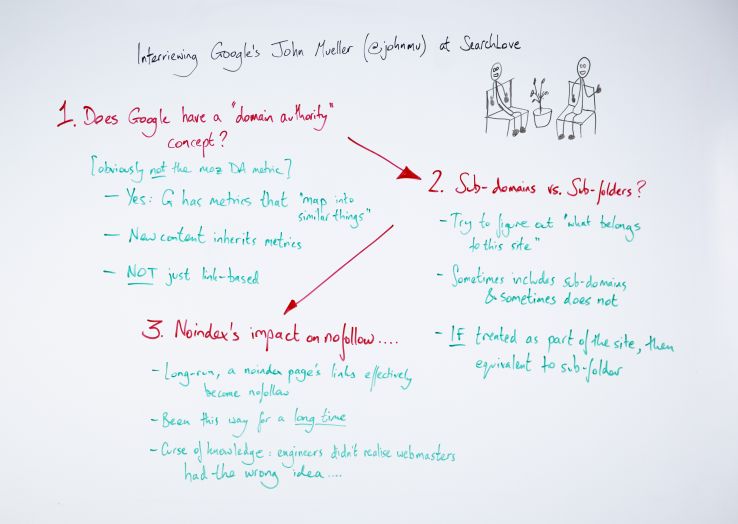
1. Does Google have a “Domain Authority” concept?
But the first thing that I wanted to quiz John about was this domain authority idea. So here we are on Moz. Moz has a proprietary metric called domain authority, DA. I feel like when, as an industry, we’ve asked Google, and John in particular, about this kind of thing in the past, does Google have a concept of domain authority, it’s got bundled up with feeling like, oh, he’s had an easy way out of being able to answer and say, “No, no, that’s a proprietary Moz metric. We don’t have that.”
I felt like that had got a bit confusing, because our suspicion is that there is some kind of an authority or a trust metric that Google has and holds at a domain level. We think that’s true, but we felt like they had always been able to wriggle out of answering the question. So I said to John, “Okay, I am not asking you do you use Moz’s domain authority metric in your ranking factors. Like we know that isn’t the case. But do you have something a little bit like it?”
Yes, Google has metrics that map into similar things
John said yes. He said yes, they have metrics that, his exact quote was, “map into similar things.”My way of phrasing this was this is stuff that is at the domain level. It’s based on things like link authority, and it is something that is used to understand performance or to rank content across an entire domain. John said yes, they have something similar to that.
New content inherits those metrics
They use it in particular when they discover new content on an existing domain. New content, in some sense, can inherit some of the authority from the domain, and this is part of the reason why we figured they must have something like this, because we’ve seen identical content perform differently on different sites. We know that there’s something to this. So yes, John confirmed that until they have some of those metrics developed, when they’ve seen a bit of content for long enough, and it can have its own link metrics and usage metrics, in the intervening time up until that point it can inherit some of this stuff from the domain.
Not wholly link-based
He did also just confirm that it’s not just link-based. This is not just a domain-level PageRank type thing.
2. Subdomains versus subfolders
This led me into the second thing that I really wanted to get out of him, which was — and when I raised this, I got kind of an eye roll, “Are we really going down this rabbit hole” — the subdomain versus subfolder question. You might have seen me talk about this. You might have seen people like Rand talk about this, where we’ve seen cases and we have case studies of moving blog.example.com to example.com/blog and changing nothing else and getting an uplift.
We know something must be going on, and yet the official line out of Google has for a very long time been: “We don’t treat these things differently. There is nothing special about subfolders. We’re perfectly happy with subdomains. Do whatever is right for your business.” We’ve had this kind of back-and-forth a few times. The way I put it to John was I said, “We have seen these case studies. How would you explain this?”
They try to figure out what belongs to the site
To his credit, John said, “Yes, we’ve seen them as well.” So he said, yes, Google has also seen these things. He acknowledged this is true. He acknowledged that it happens. The way he explained it connects back into this Domain Authority thing in my mind, which is to say that the way they think about it is: Are these pages on this subdomain part of the same website as things on the main domain?
That’s kind of the main question. They try and figure out, as he put it, “what belongs to this site.” We all know of sites where subdomains are entirely different sites. If you think about a blogspot.com or a WordPress.com domain, subdomains might be owned and managed by entirely different people, and there would be no reason for that authority to pass across. But what Google is trying to do and is trying to say, “Is this subdomain part of this main site?”
Sometimes this includes subdomains and sometimes not
He said sometimes they determine that it is, and sometimes they determine that it is not. If it is part of the site, in their estimation, then they will treat it as equivalent to a subfolder. This, for me, pretty much closes this loop. I think we understand each other now, which is Google is saying, in these certain circumstances, they will be treated identically, but there are circumstances where it can be treated differently.
My recommendation stays what it’s always been, which is 100% if you’re starting from the outset, put it on a subfolder. There’s no upside to the subdomain. Why would you risk the fact that Google might treat it as a separate site? If it is currently on a subdomain, then it’s a little trickier to make that case. I would personally be arguing for the integration and for making that move.
If it’s treated as part of the site, a subdomain is equivalent to a subfolder
But unfortunately, but somewhat predictably, I couldn’t tie John down to any particular way of telling if this is the case. If your content is currently on a subdomain, there isn’t really any way of telling if Google is treating it differently, which is a shame, but it’s somewhat predictable. But at least we understand each other now, and I think we’ve kind of got to the root of the confusion. These case studies are real. This is a real thing. Certainly in certain circumstances moving from the subdomain to the subfolder can improve performance.
3. Noindex’s impact on nofollow
The third thing that I want to talk about is a little bit more geeked out and technical, and also, in some sense, it leads to some bigger picture lessons and thinking. A little while ago John kind of caught us out by talking about how if you have a page that you no index and keep it that way for a long time, that Google will eventually treat that equivalently to a no index, no follow.
In the long-run, a noindex page’s links effectively become nofollow
In other words, the links off that page, even if you’ve got it as a no index, follow, the links off that page will be effectively no followed. We found that a little bit confusing and surprising. I mean I certainly felt like I had assumed it didn’t work that way simply because they have the no index, follow directive, and the fact that that’s a thing seems to suggest that it ought to work that way.
It’s been this way for a long time
It wasn’t really so much about the specifics of this, but more the like: How did we not know this? How did this come about and so forth? John talked about how, firstly, it has been this way for a long time. I think he was making the point none of you all noticed, so how big a deal can this really be? I put it back to him that this is kind of a subtle thing and very hard to test, very hard to extract out the different confounding factors that might be going on.
I’m not surprised that, as an industry, we missed it. But the point being it’s been this way for a long time, and Google’s view and certainly John’s view was that this hadn’t been hidden from us so much as the people who knew this hadn’t realized that they needed to tell anyone. The actual engineers working on the search algorithm, they had a curse of knowledge.
The curse of knowledge: engineers didn’t realize webmasters had the wrong idea
They knew it worked this way, and they had never realized that webmasters didn’t know that or thought any differently. This was one of the things that I was kind of trying to push to John a little more was kind of saying, “More of this, please. Give us more access to the engineers. Give us more insight into their way of thinking. Get them to answer more questions, because then out of that we’ll spot the stuff that we can be like, ‘Oh, hey, that thing there, that was something I didn’t know.’ Then we can drill deeper into that.”
That led us into a little bit of a conversation about how John operates when he doesn’t know the answer, and so there were some bits and pieces that were new to me at least about how this works. John said he himself is generally not attending search quality meetings. The way he works is largely off his knowledge and knowledge base type of content, but he has access to engineers.
They’re not dedicated to the webmaster relations operation. He’s just going around the organization, finding individual Google engineers to answer these questions. It was somewhat interesting to me at least to find that out. I think hopefully, over time, we can generally push and say, “Let’s look for those engineers. John, bring them to the front whenever they want to be visible, because they’re able to answer these kinds of questions that might just be that curse of knowledge that they knew this all along and we as marketers hadn’t figured out this was how things worked.”
That was my quick run-through of some of the things that I learned when I interviewed John. We’ll link over to more resources and transcripts and so forth. But it’s been a blast. Take care.
- Further reading: Interviewing Google’s John Mueller at SearchLove: domain authority metrics, sub-domains vs. sub-folders and more
Video transcription by Speechpad.com
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()