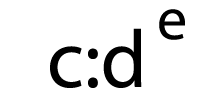
Posted by goralewicz
I was recently challenged with a question from a client, Robert, who runs a small PR firm and needed to optimize a client’s website. His question inspired me to run a small experiment in HTTP protocols. So what was Robert’s question? He asked…
Can Googlebot crawl using HTTP/2 protocols?
You may be asking yourself, why should I care about Robert and his HTTP protocols?
As a refresher, HTTP protocols are the basic set of standards allowing the World Wide Web to exchange information. They are the reason a web browser can display data stored on another server. The first was initiated back in 1989, which means, just like everything else, HTTP protocols are getting outdated. HTTP/2 is one of the latest versions of HTTP protocol to be created to replace these aging versions.
So, back to our question: why do you, as an SEO, care to know more about HTTP protocols? The short answer is that none of your SEO efforts matter or can even be done without a basic understanding of HTTP protocol. Robert knew that if his site wasn’t indexing correctly, his client would miss out on valuable web traffic from searches.
The hype around HTTP/2
HTTP/1.1 is a 17-year-old protocol (HTTP 1.0 is 21 years old). Both HTTP 1.0 and 1.1 have limitations, mostly related to performance. When HTTP/1.1 was getting too slow and out of date, Google introduced SPDY in 2009, which was the basis for HTTP/2. Side note: Starting from Chrome 53, Google decided to stop supporting SPDY in favor of HTTP/2.
HTTP/2 was a long-awaited protocol. Its main goal is to improve a website’s performance. It’s currently used by 17% of websites (as of September 2017). Adoption rate is growing rapidly, as only 10% of websites were using HTTP/2 in January 2017. You can see the adoption rate charts here. HTTP/2 is getting more and more popular, and is widely supported by modern browsers (like Chrome or Firefox) and web servers (including Apache, Nginx, and IIS).
Its key advantages are:
- Multiplexing: The ability to send multiple requests through a single TCP connection.
- Server push: When a client requires some resource (let’s say, an HTML document), a server can push CSS and JS files to a client cache. It reduces network latency and round-trips.
- One connection per origin: With HTTP/2, only one connection is needed to load the website.
- Stream prioritization: Requests (streams) are assigned a priority from 1 to 256 to deliver higher-priority resources faster.
- Binary framing layer: HTTP/2 is easier to parse (for both the server and user).
- Header compression: This feature reduces overhead from plain text in HTTP/1.1 and improves performance.
For more information, I highly recommend reading “Introduction to HTTP/2” by Surma and Ilya Grigorik.
All these benefits suggest pushing for HTTP/2 support as soon as possible. However, my experience with technical SEO has taught me to double-check and experiment with solutions that might affect our SEO efforts.
So the question is: Does Googlebot support HTTP/2?
Google’s promises
HTTP/2 represents a promised land, the technical SEO oasis everyone was searching for. By now, many websites have already added HTTP/2 support, and developers don’t want to optimize for HTTP/1.1 anymore. Before I could answer Robert’s question, I needed to know whether or not Googlebot supported HTTP/2-only crawling.
I was not alone in my query. This is a topic which comes up often on Twitter, Google Hangouts, and other such forums. And like Robert, I had clients pressing me for answers. The experiment needed to happen. Below I’ll lay out exactly how we arrived at our answer, but here’s the spoiler: it doesn’t. Google doesn’t crawl using the HTTP/2 protocol. If your website uses HTTP/2, you need to make sure you continue to optimize the HTTP/1.1 version for crawling purposes.
The question
It all started with a Google Hangouts in November 2015.
When asked about HTTP/2 support, John Mueller mentioned that HTTP/2-only crawling should be ready by early 2016, and he also mentioned that HTTP/2 would make it easier for Googlebot to crawl pages by bundling requests (images, JS, and CSS could be downloaded with a single bundled request).
“At the moment, Google doesn’t support HTTP/2-only crawling (…) We are working on that, I suspect it will be ready by the end of this year (2015) or early next year (2016) (…) One of the big advantages of HTTP/2 is that you can bundle requests, so if you are looking at a page and it has a bunch of embedded images, CSS, JavaScript files, theoretically you can make one request for all of those files and get everything together. So that would make it a little bit easier to crawl pages while we are rendering them for example.”
Soon after, Twitter user Kai Spriestersbach also asked about HTTP/2 support: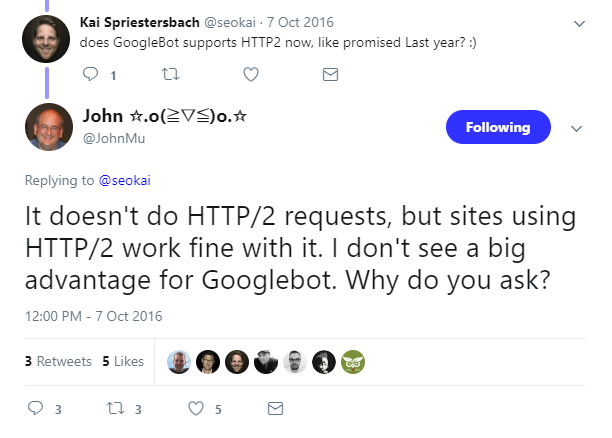
His clients started dropping HTTP/1.1 connections optimization, just like most developers deploying HTTP/2, which was at the time supported by all major browsers.
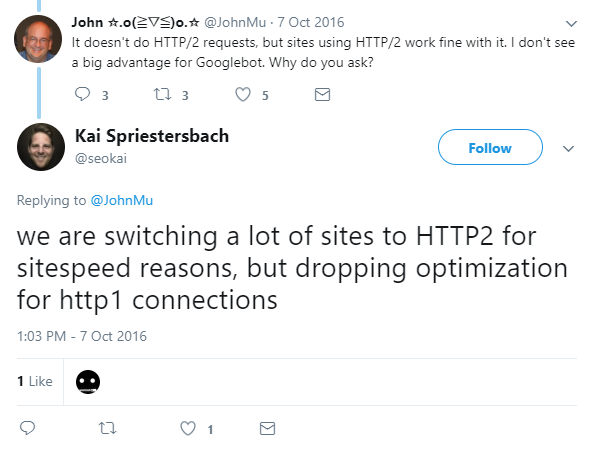
After a few quiet months, Google Webmasters reignited the conversation, tweeting that Google won’t hold you back if you’re setting up for HTTP/2. At this time, however, we still had no definitive word on HTTP/2-only crawling. Just because it won’t hold you back doesn’t mean it can handle it — which is why I decided to test the hypothesis.
The experiment
For months as I was following this online debate, I still received questions from our clients who no longer wanted want to spend money on HTTP/1.1 optimization. Thus, I decided to create a very simple (and bold) experiment.
I decided to disable HTTP/1.1 on my own website (https://goralewicz.com) and make it HTTP/2 only. I disabled HTTP/1.1 from March 7th until March 13th.
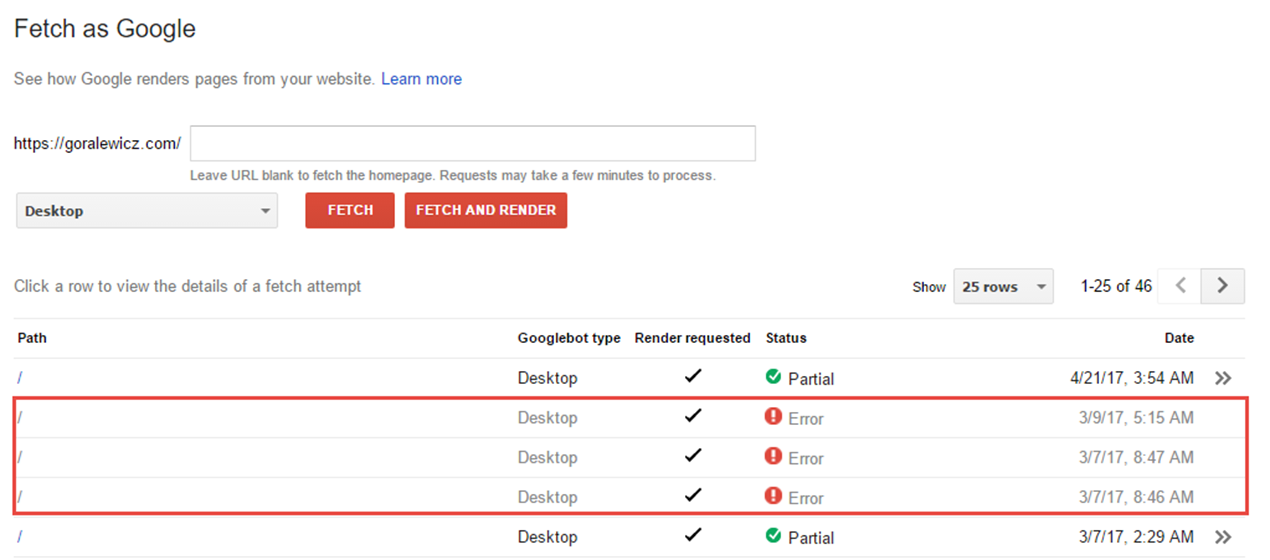
If you’re going to get bad news, at the very least it should come quickly. I didn’t have to wait long to see if my experiment “took.” Very shortly after disabling HTTP/1.1, I couldn’t fetch and render my website in Google Search Console; I was getting an error every time.
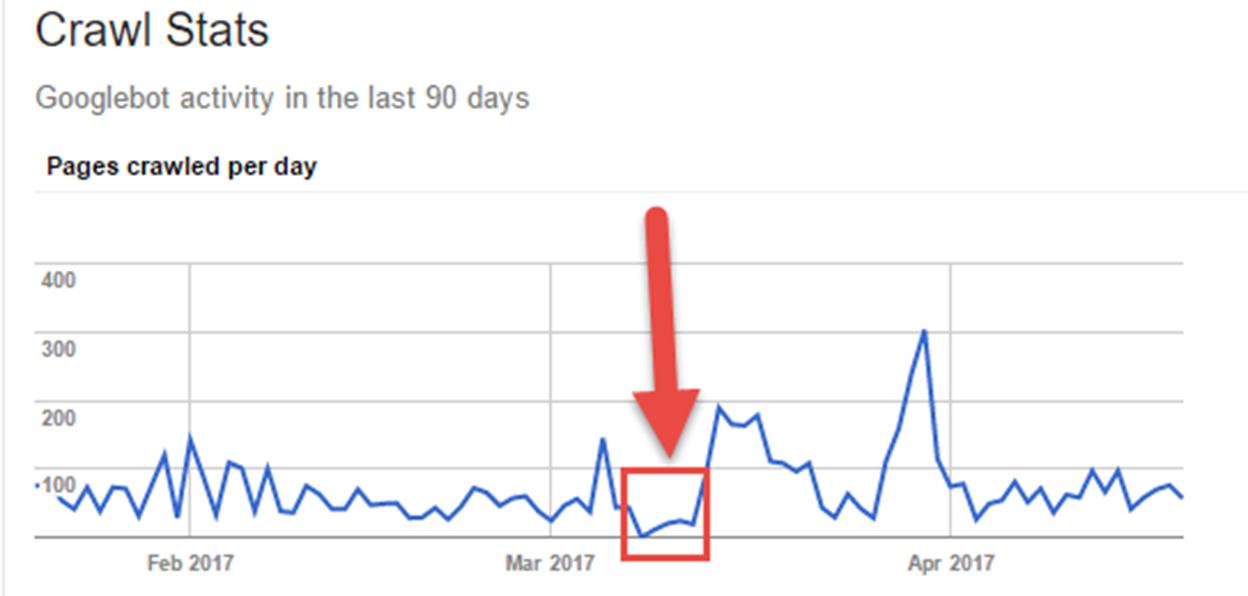
My website is fairly small, but I could clearly see that the crawling stats decreased after disabling HTTP/1.1. Google was no longer visiting my site.
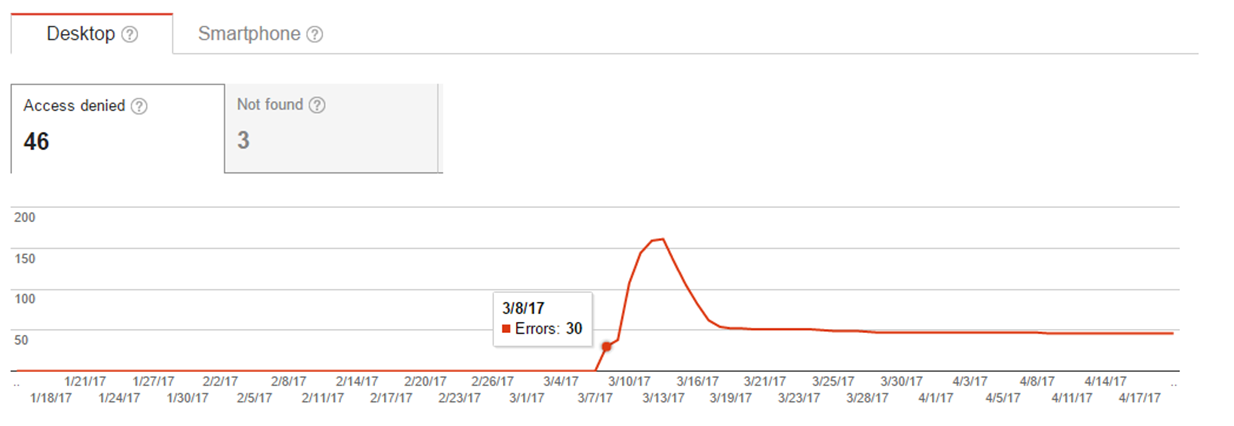
While I could have kept going, I stopped the experiment after my website was partially de-indexed due to “Access Denied” errors.
The results
I didn’t need any more information; the proof was right there. Googlebot wasn’t supporting HTTP/2-only crawling. Should you choose to duplicate this at home with our own site, you’ll be happy to know that my site recovered very quickly.
I finally had Robert’s answer, but felt others may benefit from it as well. A few weeks after finishing my experiment, I decided to ask John about HTTP/2 crawling on Twitter and see what he had to say.
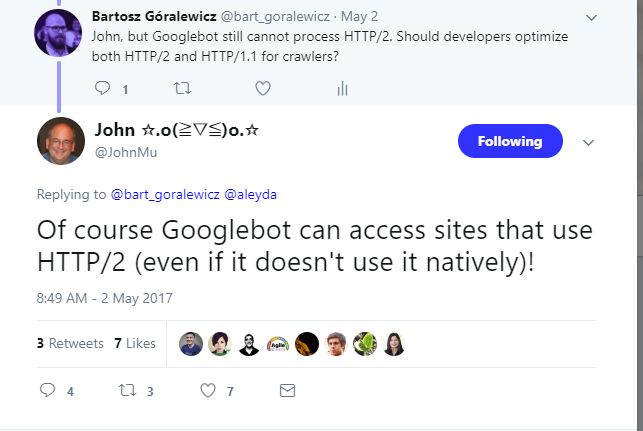
(I love that he responds.)
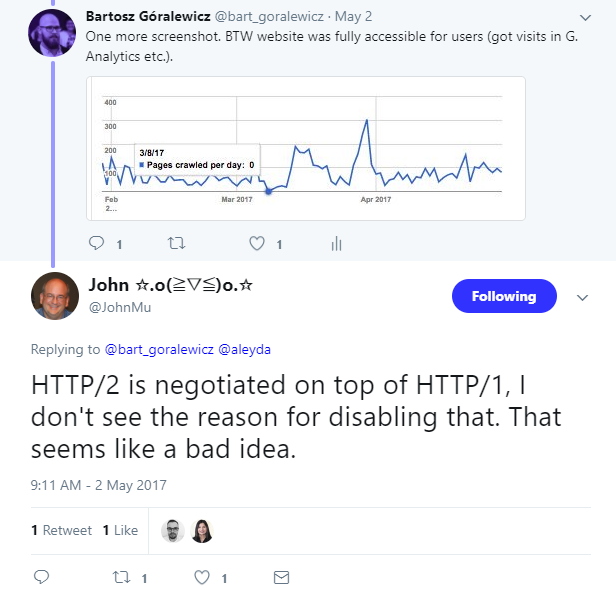
Knowing the results of my experiment, I have to agree with John: disabling HTTP/1 was a bad idea. However, I was seeing other developers discontinuing optimization for HTTP/1, which is why I wanted to test HTTP/2 on its own.
For those looking to run their own experiment, there are two ways of negotiating a HTTP/2 connection:
1. Over HTTP (unsecure) – Make an HTTP/1.1 request that includes an Upgrade header. This seems to be the method to which John Mueller was referring. However, it doesn’t apply to my website (because it’s served via HTTPS). What is more, this is an old-fashioned way of negotiating, not supported by modern browsers. Below is a screenshot from Caniuse.com:

2. Over HTTPS (secure) – Connection is negotiated via the ALPN protocol (HTTP/1.1 is not involved in this process). This method is preferred and widely supported by modern browsers and servers.
A recent announcement: The saga continues
Googlebot doesn’t make HTTP/2 requests
Fortunately, Ilya Grigorik, a web performance engineer at Google, let everyone peek behind the curtains at how Googlebot is crawling websites and the technology behind it:
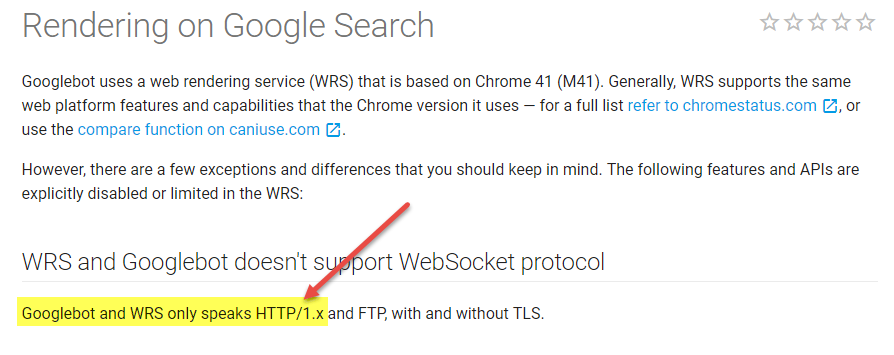
If that wasn’t enough, Googlebot doesn’t support the WebSocket protocol. That means your server can’t send resources to Googlebot before they are requested. Supporting it wouldn’t reduce network latency and round-trips; it would simply slow everything down. Modern browsers offer many ways of loading content, including WebRTC, WebSockets, loading local content from drive, etc. However, Googlebot supports only HTTP/FTP, with or without Transport Layer Security (TLS).
Googlebot supports SPDY
During my research and after John Mueller’s feedback, I decided to consult an HTTP/2 expert. I contacted Peter Nikolow of Mobilio, and asked him to see if there were anything we could do to find the final answer regarding Googlebot’s HTTP/2 support. Not only did he provide us with help, Peter even created an experiment for us to use. Its results are pretty straightforward: Googlebot does support the SPDY protocol and Next Protocol Navigation (NPN). And thus, it can’t support HTTP/2.
Below is Peter’s response:
I performed an experiment that shows Googlebot uses SPDY protocol. Because it supports SPDY + NPN, it cannot support HTTP/2. There are many cons to continued support of SPDY:
- This protocol is vulnerable
- Google Chrome no longer supports SPDY in favor of HTTP/2
- Servers have been neglecting to support SPDY. Let’s examine the NGINX example: from version 1.95, they no longer support SPDY.
- Apache doesn’t support SPDY out of the box. You need to install mod_spdy, which is provided by Google.
To examine Googlebot and the protocols it uses, I took advantage of s_server, a tool that can debug TLS connections. I used Google Search Console Fetch and Render to send Googlebot to my website.
Here’s a screenshot from this tool showing that Googlebot is using Next Protocol Navigation (and therefore SPDY):
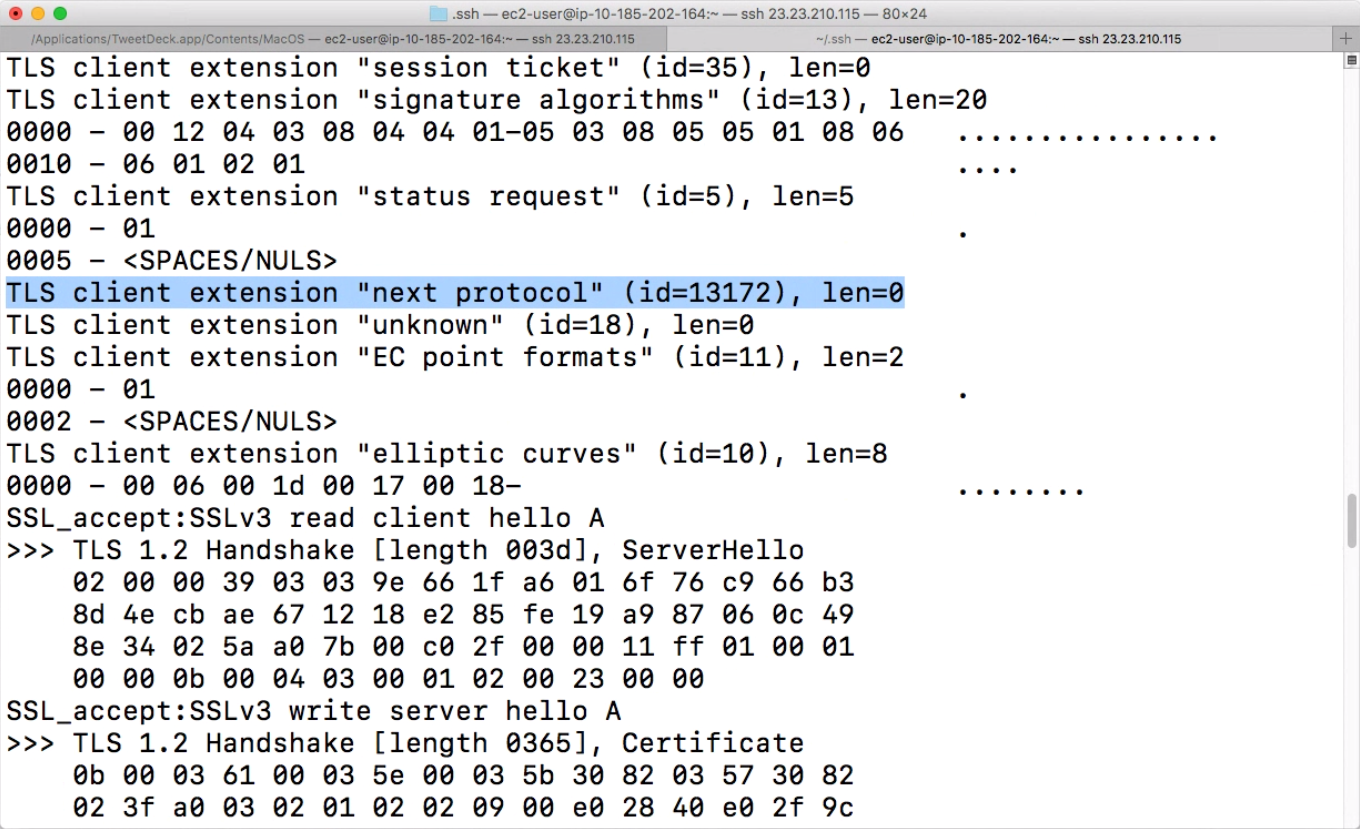
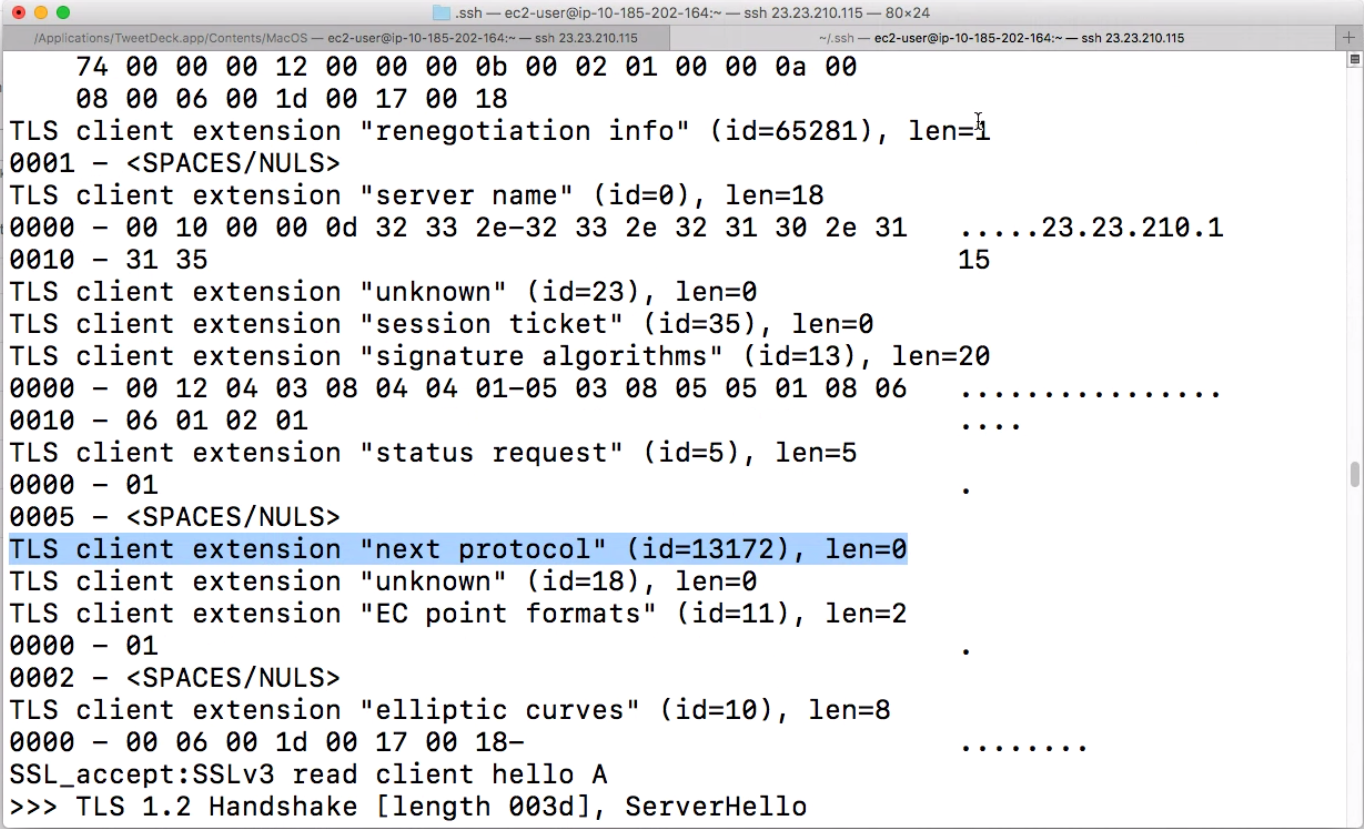
I’ll briefly explain how you can perform your own test. The first thing you should know is that you can’t use scripting languages (like PHP or Python) for debugging TLS handshakes. The reason for that is simple: these languages see HTTP-level data only. Instead, you should use special tools for debugging TLS handshakes, such as s_server.
Type in the console:
sudo openssl s_server -key key.pem -cert cert.pem -accept 443 -WWW -tlsextdebug -state -msg sudo openssl s_server -key key.pem -cert cert.pem -accept 443 -www -tlsextdebug -state -msg
Please note the slight (but significant) difference between the “-WWW” and “-www” options in these commands. You can find more about their purpose in the s_server documentation.
Next, invite Googlebot to visit your site by entering the URL in Google Search Console Fetch and Render or in the Google mobile tester.
As I wrote above, there is no logical reason why Googlebot supports SPDY. This protocol is vulnerable; no modern browser supports it. Additionally, servers (including NGINX) neglect to support it. It’s just a matter of time until Googlebot will be able to crawl using HTTP/2. Just implement HTTP 1.1 + HTTP/2 support on your own server (your users will notice due to faster loading) and wait until Google is able to send requests using HTTP/2.
Summary
In November 2015, John Mueller said he expected Googlebot to crawl websites by sending HTTP/2 requests starting in early 2016. We don’t know why, as of October 2017, that hasn’t happened yet.
What we do know is that Googlebot doesn’t support HTTP/2. It still crawls by sending HTTP/ 1.1 requests. Both this experiment and the “Rendering on Google Search” page confirm it. (If you’d like to know more about the technology behind Googlebot, then you should check out what they recently shared.)
For now, it seems we have to accept the status quo. We recommended that Robert (and you readers as well) enable HTTP/2 on your websites for better performance, but continue optimizing for HTTP/ 1.1. Your visitors will notice and thank you.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don’t have time to hunt down but want to read!
![]()